Quarantine - Code-id 19 May 15, 2020
Coronavirus has been a very productive time for me! I have used it to complete some woodworking projects, and have coded up many helpful tools in Go, of course. Recent problems have revolved around databases being out of sync, configuration complexities, and trying to copy large files over the network that would fail half way through.
For two months now, we've been social distancing. Luckily I have a job where I can work from home. This saves me an hour at least per day in commute time. Except, now I have to home school too, but that's fun. It just takes time.
In order to be more efficient, I try to automate everything. Everything I write that is not directly doing work for a work project, is doing something to make me more efficient and also limit the amount of grunt work I would have to do.
Recent Problems
Dev content is out of sync!
Solution: Write a dbsync tool. Luckily the db we deal with mostly has no identity insert auto incremented integer id fields. This makes it easier. The thing that makes it harder is that the dbs for which I wrote this tool have millions of rows, are frequently updated, and have blobs that are multiple megabytes in size. This one I haven't made public. But it will take a config of two connection strings, one is the source, one is the destination, then it will also have table definitions along with a timestamp field to be able to tell which rows have been updated since the last time the tool ran. When it reads all of the rows from the source table, it will update the time stamp so it gets much less data the next time. I just run these occasionally for all of the different databases that I have to manage. Having up to date content for development is a headache reducer.

Configuration is complex!!
Sitecore uses about a hundred configuration files. We have to keep track of different settings across multiple environments, like development content management and a separate content delivery, then the same thing for UAT, and the a more complex configuration set for production, with a CM and two CD servers typically. I solved this during a build by having a build process take all of the base Sitecore configs, then copy over application specific configuration, then finally copy over environment specific configuration. Then a separate process deletes files where there's also a .deleted file along site of it, like something.config and something.config.deleted. Then a separate processes merging updates to Web.config in the root. This is pretty useful.
The main problem with this is that if we inherit a site, or want to convert an older site that didn't use this configuration process. So I made a config split tool! So you have a folder with all of the Sitecore configuration files, then each environment's configuration files in other folders, and run cfgsplit with the proper parameters. It will remove all the files that are the same across all of the folders. Then you run another pass at it with slightly different parameters, and it will move all configs that are the same from the environment configuration files into a separate application specific configuration folder, where all of those configuration files are the same. After that you're pretty much done.
The other aspect of this is the Web.config. There's a similar process with this except it works on XML, not folder structures. The idea is the same though. However, some XML nodes are extremely tricky to figure out a unique identifier for. Like, where the b node is the same across many different instances of y, and where y never has any attributes but there are multiple in succession. You might think using indexes might be a good idea. But, we're comparing whether these nodes exist in the other file, and having them be identified by index would not match the other files, so I had to match by content.
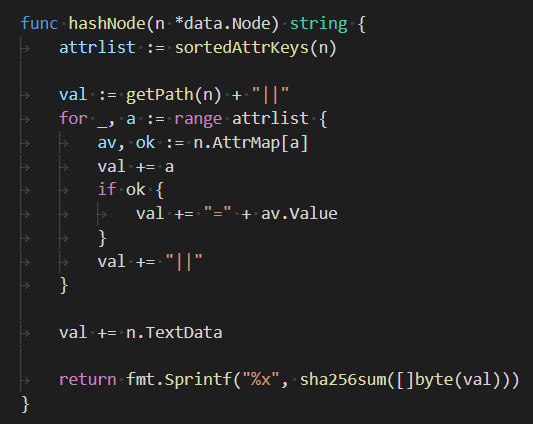
For a node like x or y, I would grab a hash of the children's contents. This was a good unique identifier. For a node like b, I had to grab a hash of the siblings. If there are two identical y nodes under this specific x, my code will fail. But you can argue when that would be useful, having two identical nodes as siblings in XML. I won't share this code either. It is nearly complete.
A File is too big to copy over RDP!
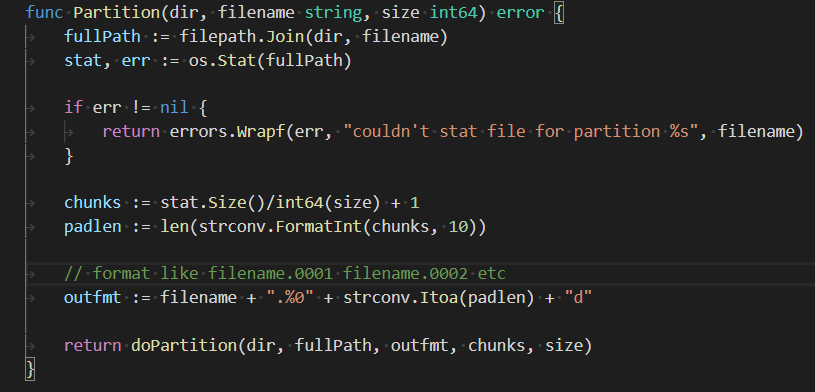
This one was a fun one and only took me an hour. I was heavily inspired from my memories of downloading "warez" in college, where you'd get a RAR file as a bunch of files, instead of one large one. This code I can share, it is here. I simply call it parts. It just does that, takes a file and splits it into chunks whose size is passed in via a parameter. There's no check on that size, now that I think about it, but I can check to see how many chunks would result and maybe throw an error if that's over an arbitrary limit, like 100 or something. But if you want to create 2 billion files, go ahead.
Happy coding!